
In this article, we will look at how to extract product information from aliexpress.com. Note that this is a very interesting task – aliexpress is very large, consists of many modules, and combines several platforms for content hosting. Classic solutions are often not suitable for fully extracting data from this site. Making a scraper for the aliexpress is a non-standard task, as the site is complex and requires additional work with elements before extracting data.
After reading this article, you will be able to extract data from Aliexpress automatically using our application.
Please note that this article has a significant technical gradient. If you just need to make data scraper for Aliexpress website without unnecessary reading, you can go to the quick instructions at the end of this article or just contact our support.
Want to extract data from websites? You will need basic technical knowledge about .CSS selectors. You can find general information here (third-party site). In general, an understanding of .CSS selectors will help you to solve any task on information scraping.
Attention! This article is relevant for May 2020. All sites sometimes change their layout and the way they present information. If you now find that the method proposed here does not work, please let us know and we will quickly make changes. This is our job, and we try to keep the configuration repository up to date. Thank you!
Product page features
The product page on Aliexpress has an amazingly minimalistic look. See for yourself – each item on this page is designed and contains only useful features! If you look at the page, you will find that there is no unnecessary – only actual information about the product and the seller.
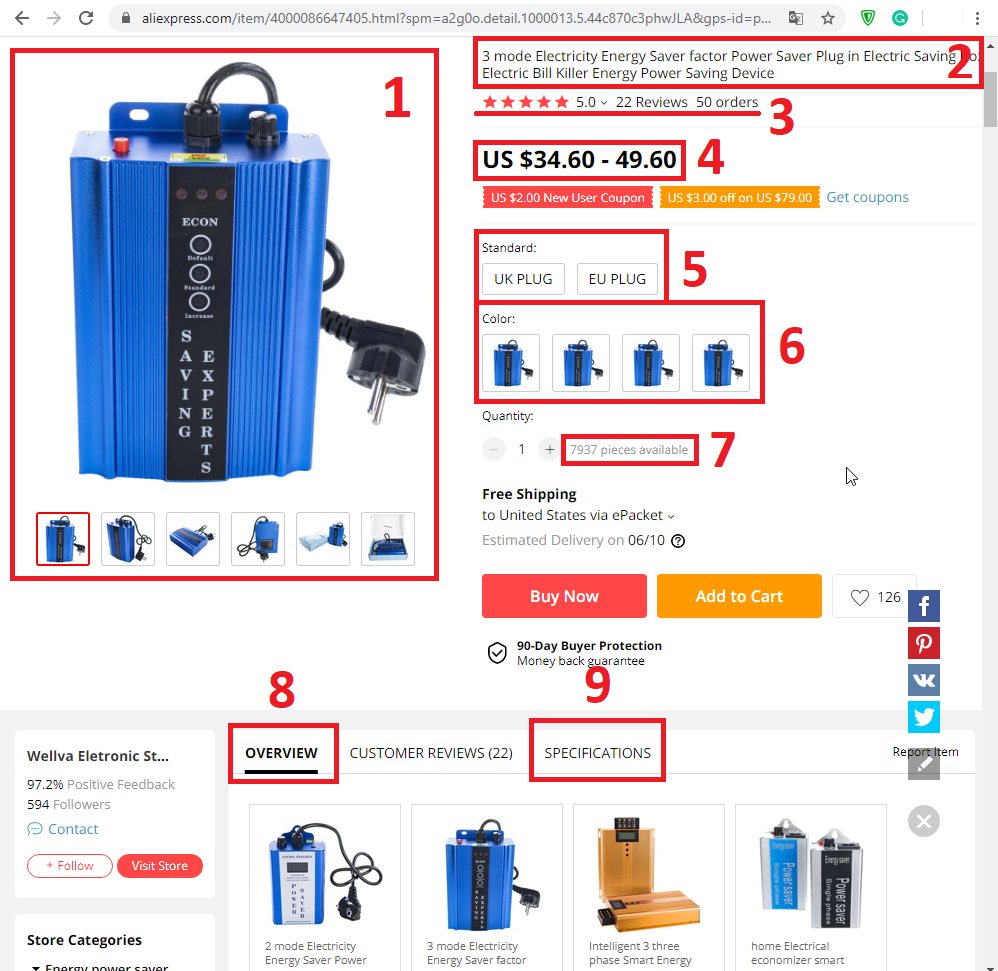
However, the Aliexpress product pages have some features that you cannot ignore. The scraper for the aliexpress must first take these features into account and only then extract the data.
So, first, let’s describe all the features of the aliexpress site. Let’s consider the list of problems that we encountered when creating the script to parse this site.
- Content on the site is displayed using JavaScript, a few seconds after loading the page.
- Product pictures are displayed in a preview “one at a time”. In this way, we can either retrieve the “micro pictures” or come up with another way to retrieve the data.
- The aliexpress site uses a multi-domain structure depending on the language. Thus, if you browse the site in Italy, you see the Italian version of the site with the subdomain it. If you are browsing in France, you will see the French version of the site with the subdomain fr. So, if you need to extract data with some specific language, you will have to invent something.
- Some product information is located on distributed services and domains that are different from the main domain. This also needs attention because we actually need to extract data from multiple sites at the same time.
- Product characteristics (Param = Value, like a “Color = Blue”) are represented by a complex HTML table, and for qualitative extraction of product characteristics we will need a good algorithm for processing this table.
- The description of the product is usually presented as a set of images. Also, the product description is uploaded to the product page on a separate link, which leads to one of the services of information storage. This is another additional factor that makes it necessary to index several resources at once.
- Content is uploaded to the page gradually, as the page is scrolled down. Accordingly, if you just load a page and try to extract data from it through a visual scraper – nothing happens, most of the page will be empty. Scrolling should be done so that the page is scrolled to the description and features.
- There are many “blank” images on the page. Often, many sellers insert transparent blocks with an image as elements of the layout. The same goes for the site itself. We are not sure that this is a good idea and a good way to organize the appearance. However, we don’t need these empty transparent cubes, and we’ll have to filter them out somehow.
In general, the problems listed are not a significant barrier to data extraction. They are simply site features that need to be resolved. We tried to solve this problem in the easiest way. Below we offer your views on how to extract data from aliexpress.
The idea
Our decision does not claim to be unique. However, it combines the technology of linear data scraping and some automation. The actual trick is that Aliexpress stores product data in a JavaScript container, which is available on the product page. This object contains most of the necessary information. Accordingly, our Aliexpress scraper takes some data from the page itself (directly from HTML markup), and some data from this JavaScript container.
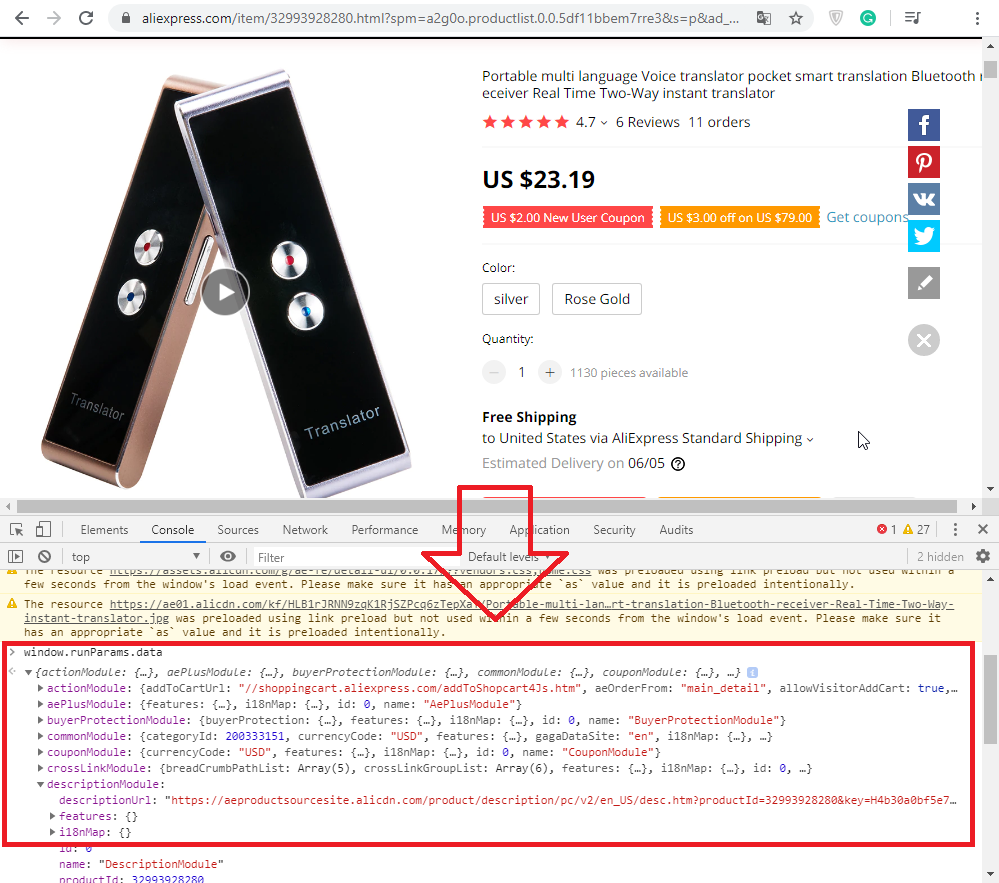
Of course, the presence of this container does not relieve us from the need to solve other tasks – downloading images, downloading product descriptions, forming a list of parameters, etc. The container somewhat simplifies data scraping and speeds it up.
The name of the container is window.runParams.data
Then we found the following behavior. It is initialized when the page is loaded and stays on it all the time. When you scroll down a page, some elements of the page appearance are generated from this data.
The JS object itself also contains some features. In particular, descriptions of goods are stored in a separate subdomain – https://aeproductsourcesite.alicdn.com, and are loaded from there. Accordingly, you can find a link to the description of the goods inside the container by the following name: window.runParams.data.descriptionModule.descriptionUrl . How you can understand, you can download data manually by following the link above, or scrape data from the product page directly after renderer will be worked.
In general, we decided to use both methods of data extraction from the page – both from the page itself and from JS-container. It is more convenient than manually processing the whole container, but at the same time much faster than extracting data only from the page.
Aliexpress scraper – concept
So, the concept of our AliExpress scraping algorithm is as follows. We will not index the page description separately, but wait for the page to load. As for images, we will do the opposite – we will not extract them from the page and will not emulate preview clicks. We will take references to images from JS data container.
But what about it? Above the text, we wrote that the content is drawn on the page is not immediately, and you need to scroll down the page to the site drew a description and other elements. Fortunately, our program can process JS as part of data scraping from each page. Thus, our Aliexpress scraper can be equipped with its own script, which will be executed on each page.
Note that our scraping server is based, among other things, on the Chromium browser. It allows us to execute any JS scripts when interacting with any pages. In fact, you can do anything with a page – authentication, scrolling, clicks. In this case, the browser window itself is hidden from you inside the kernel of the program, and the program can be rolled up into tray in the course of its work.
Accordingly, our aliexpress scraper concept is that we will need additional JavaScript processing that will run on each page before we extract the data. This script will prepare the data in a more convenient way to extract it. Let us look at the main nodes of our script and the problems that these nodes will solve.
Common algorithm steps
A. Scroll to description
After loading the page, we’ll scroll it down. We can do it through a set of multiple timeouts, which are performed one after another. Why multiple scrolling operations? Because when we perform only one operation, we “jump” the element where the rest of the page starts loading and the elements stop loading. Thus, to scrape the description from the Aliexpress product page, we need exactly a few consecutive scrolls down.
/* Scroll page to bottom */
setTimeout(function() { window.scrollTo( 0, 1000 ); }, 1000);
setTimeout(function() { window.scrollTo( 0, 2500 ); }, 3000);
setTimeout(function() { window.scrollTo( 0, 5000 ); }, 6000);
setTimeout(function() { window.scrollTo( 0, 6500 ); }, 8000);B. Removing empty images
Well, now we need to remove the unnecessary blank images that make up the page markup and description. To do that, we’ll need another timeout – just after scrolling down.
/* Remove empty images */
setTimeout(function() {
document.querySelectorAll(img[src='https://ae01.alicdn.com/kf/HTB13SZpXpP7gK0jSZFj7635aXXaw.png']).forEach(function(elementData) { elementData.remove(); });
}, 8500);C. Assembling lmages from JS container
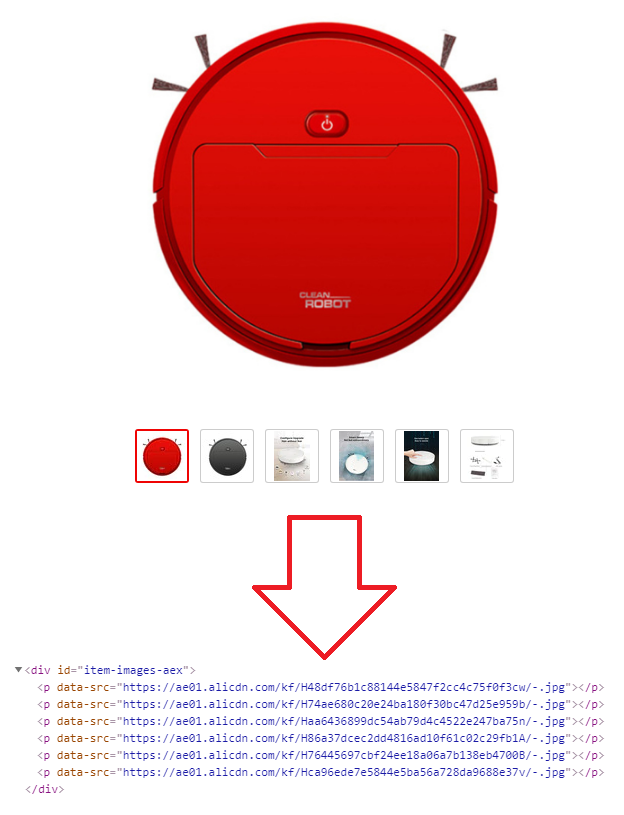
Now we move on to extracting the pictures. As we wrote above, the pictures on the product page are stored as previews. In terms of normal scraping, we should click on each picture and get it out. But we’ll do it more elegantly. We’ll go to the window.runParams.data JS container and get the link from there. After that, we will preform an HTML element directly on the page, in which we will write all found links. And already from this container, located directly on the Aliexpress page, our scraper will take the data during extraction.
And that’s what the code that extracts the pictures and packs them into a separate container looks like.
/* Prepare images from main framg / / Prepare SRCbar */
var imagesBarElement = document.createElement('div');
imagesBarElement.setAttribute('id', 'item-images-aex');
document.body.appendChild(imagesBarElement);
/* Itterate images */
window.runParams.data.imageModule.imagePathList.forEach(function(nextPathImage) {
var nextElementWithSRC = document.createElement('p');
nextElementWithSRC.setAttribute('data-src', nextPathImage);
imagesBarElement.appendChild(nextElementWithSRC);
});Accordingly, after applying this script, we get on the page here a container with links to images.
D. Extracting params
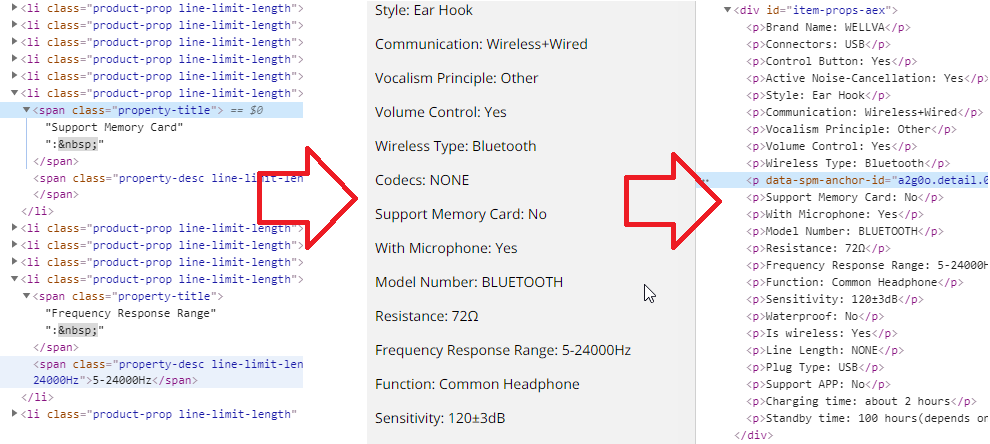
Next, we should get the product parameters. Initially, product parameters are stored as an HTML table. This is not very convenient for our purposes. It is much better to get the parameters not in the form of HTML strings, but as “Parameter: value”. To solve this problem, we also use JS code, which refers to the container with data.
/* -------------- PROPERTIES BLOCK --------------- */
/* Prepare PropsBar */
var propertiesBarElement = document.createElement('div');
propertiesBarElement.setAttribute('id', 'item-props-aex');
document.body.appendChild(propertiesBarElement);
/* Itterate props */
window.runParams.data.specsModule.props.forEach(function(nextPropData) {
var nextPropertyElement = document.createElement('p');
nextPropertyElement.innerHTML = nextPropData.attrName + ': ' + nextPropData.attrValue;
propertiesBarElement.appendChild(nextPropertyElement);
});
E. Scraping description URL
In some cases, we may need a link to the product description. We do not know how often it will be used by our customers, but we received a couple of requests about it and decided to add it inside the script.
/* ----------- PRODUCT DESCRIPTION URL ------------ */
var productDescriptionUrl = window.runParams.data.descriptionModule.descriptionUrl;
var descriptionUrlElement = document.createElement('div');
descriptionUrlElement.setAttribute('id', 'item-descriptionurl-aex');
descriptionUrlElement.setAttribute('data-url', productDescriptionUrl);
document.body.appendChild(descriptionUrlElement);Extra step – scraping product options from Aliexpress
As you know, products on AliExpress have different delivery options. For example, you can buy different products in different sizes or colors. By default, the price of one option is displayed on the product page, and to understand the price of another option you need to select its color or model.
A full-fledged aliexpress scraper should do this job. We want the result of the algorithm to give the user the maximum amount of data from the page, including all prices for possible product parameters.
We need to try to extract this data so that it can then be used in real life. Agree, it would hardly be convenient for you to pull out an entire piece of HTML code with the parameters of the product. So, what can we think of here?

The data we need is also stored in JS-container and can be accessed at window.runParams.data.skuModule. There you can find a library of all available parameters, as well as prices for each combination of these parameters. Look at the example below – you can clearly see many different parameters for the same product.
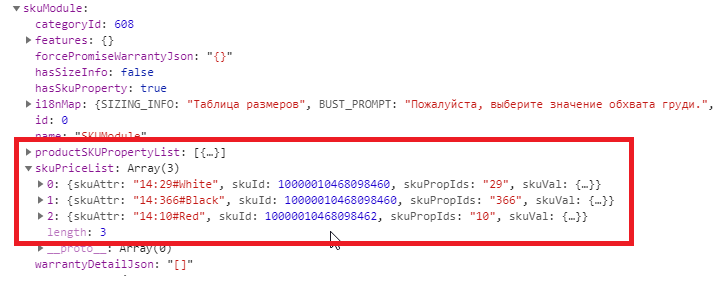
Well, it’s gonna be a little harder now. We need to extract the library of parameters, as well as all possible products with their prices and images. Parameters and prices for parameters are in separate variables, and are connected to each other via ID. We will display the results of the analysis in a simple HTML table, in a list. Let us have a look at it.
/* ------------------PRODUCT ALL SKU-------------------- */
/* Collect all SKU */
var availableProductPropertiesElement = document.createElement('div');
availableProductPropertiesElement.setAttribute('id', 'item-sku-library');
document.body.appendChild(availableProductPropertiesElement);
window.runParams.data.skuModule.productSKUPropertyList.forEach(function(nextPropertyGroup) {
var nextPropertyRow = document.createElement('p');
availableProductPropertiesElement.appendChild(nextPropertyRow);
nextPropertyRow.innerHTML = nextPropertyGroup.skuPropertyName + ': ';
var nextGroupItems = [];
nextPropertyGroup.skuPropertyValues.forEach(function(nextPropertyGroupValue) {
var nextParam = '<span ' + (typeof nextPropertyGroupValue.skuPropertyImagePath !== 'undefined' ? `data-imageurl='` + nextPropertyGroupValue.skuPropertyImagePath + `'` : '') + '>' + nextPropertyGroupValue.propertyValueDisplayName + '</span>';
nextGroupItems.push(nextParam);
});
nextPropertyRow.innerHTML += nextGroupItems.join(', ');
});
/* Collect all variants */
var availableProductsTablePriceList = d.createElement('div');
availableProductsTablePriceList.setAttribute('id', 'item-sku-pricing');
document.body.appendChild(availableProductsTablePriceList);
window.runParams.data.skuModule.skuPriceList.forEach(function(skuPriceOffer) {
var nextSKUOffer = document.createElement('p');
availableProductsTablePriceList.appendChild(nextSKUOffer);
var skuVariantFullName = [];
var skuProps = skuPriceOffer.skuPropIds.split(',');
var imageLinkIfSpecified = '';
skuProps.forEach(function(skuId) {
window.runParams.data.skuModule.productSKUPropertyList.forEach(function(nextPropertyGroup) {
nextPropertyGroup.skuPropertyValues.forEach(function(nextPropertyGroupValue) {
if (Number(nextPropertyGroupValue.propertyValueId) === Number(skuId)) {
var nextParam = '<span>' + nextPropertyGroup.skuPropertyName + ': ' + nextPropertyGroupValue.propertyValueDisplayName + '</span>';
skuVariantFullName.push(nextParam);
if (typeof nextPropertyGroupValue.skuPropertyImagePath !== 'undefined')
imageLinkIfSpecified = nextPropertyGroupValue.skuPropertyImagePath;
}
});
});
});
nextSKUOffer.innerHTML = skuVariantFullName.join(', ') + (typeof skuPriceOffer.skuVal.availQuantity !== 'undefined' ? ', Available: ' + skuPriceOffer.skuVal.availQuantity : '') + ', Price: ' + skuPriceOffer.skuVal.skuAmount.formatedAmount;
if (imageLinkIfSpecified.length > 0)
nextSKUOffer.innerHTML += ', Image: ' + imageLinkIfSpecified;
}); So, this is what we get after running this script.
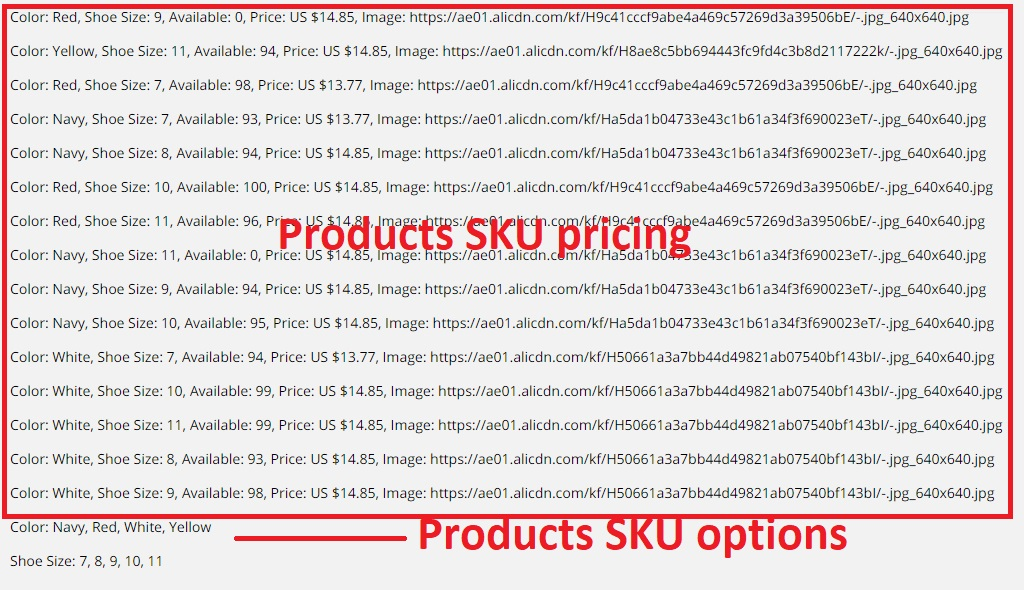
Final extraction script
Well, it’s time to build our script into one code block. You know JavaScript, right? Great, this will be a self-calling function, which will be performed on each product page, before data is scraped. After entering the page, our server will wait a couple of seconds, then execute the script, and then extract the data. Let’s see what our assembled script looks like!
(function(d) {
if (window.location.href.indexOf('item/') === -1)
return;
/* Scroll page to bottom */
setTimeout(function() { window.scrollTo( 0, 1000 ); }, 1000);
setTimeout(function() { window.scrollTo( 0, 2500 ); }, 3000);
setTimeout(function() { window.scrollTo( 0, 5000 ); }, 6000);
setTimeout(function() { window.scrollTo( 0, 6500 ); }, 8000);
/* Remove empty images */
setTimeout(function() {
d.querySelectorAll(`img[src='https://ae01.alicdn.com/kf/HTB13SZpXpP7gK0jSZFj7635aXXaw.png']`).forEach(function(elementData) { elementData.remove(); });
}, 8500);
/* -------------- IMAGES BLOCK --------------- */
/* Prepare images from main framg */
/* Prepare SRCbar */
var imagesBarElement = d.createElement('div');
imagesBarElement.setAttribute('id', 'item-images-aex');
d.body.appendChild(imagesBarElement);
/* Itterate images */
window.runParams.data.imageModule.imagePathList.forEach(function(nextPathImage) {
var nextElementWithSRC = d.createElement('p');
nextElementWithSRC.setAttribute('data-src', nextPathImage);
imagesBarElement.appendChild(nextElementWithSRC);
});
/* -------------- PROPERTIES BLOCK --------------- */
/* Prepare PropsBar */
var propertiesBarElement = d.createElement('div');
propertiesBarElement.setAttribute('id', 'item-props-aex');
d.body.appendChild(propertiesBarElement);
/* Itterate props */
window.runParams.data.specsModule.props.forEach(function(nextPropData) {
var nextPropertyElement = d.createElement('p');
nextPropertyElement.innerHTML = nextPropData.attrName + ': ' + nextPropData.attrValue;
propertiesBarElement.appendChild(nextPropertyElement);
});
/* ----------- PRODUCT DESCRIPTION URL ------------ */
var productDescriptionUrl = window.runParams.data.descriptionModule.descriptionUrl;
var descriptionUrlElement = d.createElement('div');
descriptionUrlElement.setAttribute('id', 'item-descriptionurl-aex');
descriptionUrlElement.setAttribute('data-url', productDescriptionUrl);
d.body.appendChild(descriptionUrlElement);
/* ------------------PRODUCT ALL SKU-------------------- */
/* Collect all SKU */
var availableProductPropertiesElement = d.createElement('div');
availableProductPropertiesElement.setAttribute('id', 'item-sku-library');
d.body.appendChild(availableProductPropertiesElement);
window.runParams.data.skuModule.productSKUPropertyList.forEach(function(nextPropertyGroup) {
var nextPropertyRow = d.createElement('p');
availableProductPropertiesElement.appendChild(nextPropertyRow);
nextPropertyRow.innerHTML = nextPropertyGroup.skuPropertyName + ': ';
var nextGroupItems = [];
nextPropertyGroup.skuPropertyValues.forEach(function(nextPropertyGroupValue) {
var nextParam = '<span ' + (typeof nextPropertyGroupValue.skuPropertyImagePath !== 'undefined' ? `data-imageurl='` + nextPropertyGroupValue.skuPropertyImagePath + `'` : '') + '>' + nextPropertyGroupValue.propertyValueDisplayName + '</span>';
nextGroupItems.push(nextParam);
});
nextPropertyRow.innerHTML += nextGroupItems.join(', ');
});
/* Collect all variants */
var availableProductsTablePriceList = d.createElement('div');
availableProductsTablePriceList.setAttribute('id', 'item-sku-pricing');
d.body.appendChild(availableProductsTablePriceList);
window.runParams.data.skuModule.skuPriceList.forEach(function(skuPriceOffer) {
var nextSKUOffer = d.createElement('p');
availableProductsTablePriceList.appendChild(nextSKUOffer);
var skuVariantFullName = [];
var skuProps = skuPriceOffer.skuPropIds.split(',');
var imageLinkIfSpecified = '';
skuProps.forEach(function(skuId) {
window.runParams.data.skuModule.productSKUPropertyList.forEach(function(nextPropertyGroup) {
nextPropertyGroup.skuPropertyValues.forEach(function(nextPropertyGroupValue) {
if (Number(nextPropertyGroupValue.propertyValueId) === Number(skuId)) {
var nextParam = '<span>' + nextPropertyGroup.skuPropertyName + ': ' + nextPropertyGroupValue.propertyValueDisplayName + '</span>';
skuVariantFullName.push(nextParam);
if (typeof nextPropertyGroupValue.skuPropertyImagePath !== 'undefined')
imageLinkIfSpecified = nextPropertyGroupValue.skuPropertyImagePath;
}
});
});
});
nextSKUOffer.innerHTML = skuVariantFullName.join(', ') + (typeof skuPriceOffer.skuVal.availQuantity !== 'undefined' ? ', Available: ' + skuPriceOffer.skuVal.availQuantity : '') + ', Price: ' + skuPriceOffer.skuVal.skuAmount.formatedAmount;
if (imageLinkIfSpecified.length > 0)
nextSKUOffer.innerHTML += ', Image: ' + imageLinkIfSpecified;
});
}(document));The final algorithm for scraping data from Aliexpress
So, here’s how it works when it’s assembled. We built the script and made some settings to help us extract the data. Now let’s show you the complete sequence of our scraping server. This sequence will be relevant for every page it accesses.
- The server goes to the next page, the link to which it received from the common link buffer.
- It is waiting for page loading and rendering.
- It is waiting for an additional 2 seconds until additional items are loaded.
- The server runs the script that we wrote above. The script packages the data in a convenient way and displays it on the page.
- Waiting 10 seconds – this is the time that our script will work (scroll and data container processing).
- Perform data extraction from the Aliexpress product page.
- Mark the page as completed and proceed to the next page.
Accordingly, the algorithm offered here allows to extract all data from the product page and pack them into JSON. Further, our application allows you to export results to Excel / CSV / JSON / MySQL. Yes, you can write data directly to the database – it is very convenient.
Take a look at what the execution of our algorithm looks like on the configuration test page. We just type in the link, click on the “start testing” button and get the results. Everything is very simple and clear. That’s how our scraper for aliexpress works.
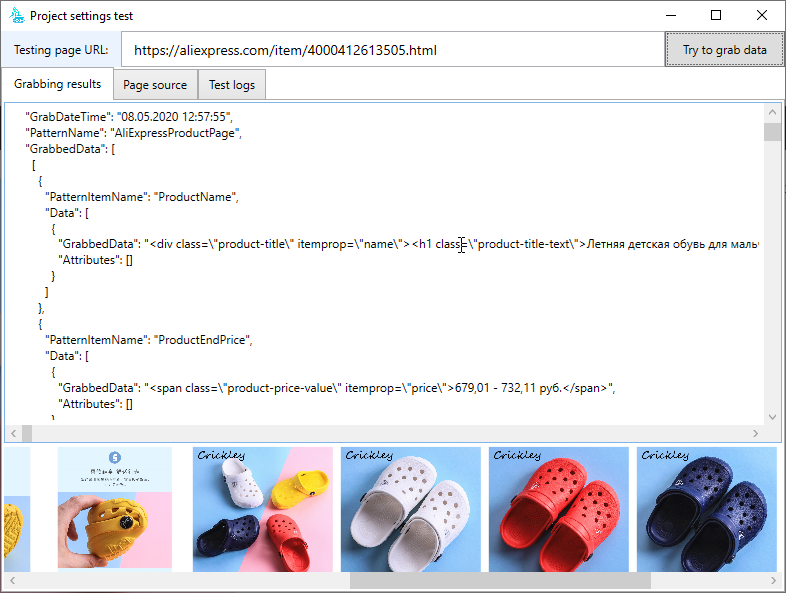
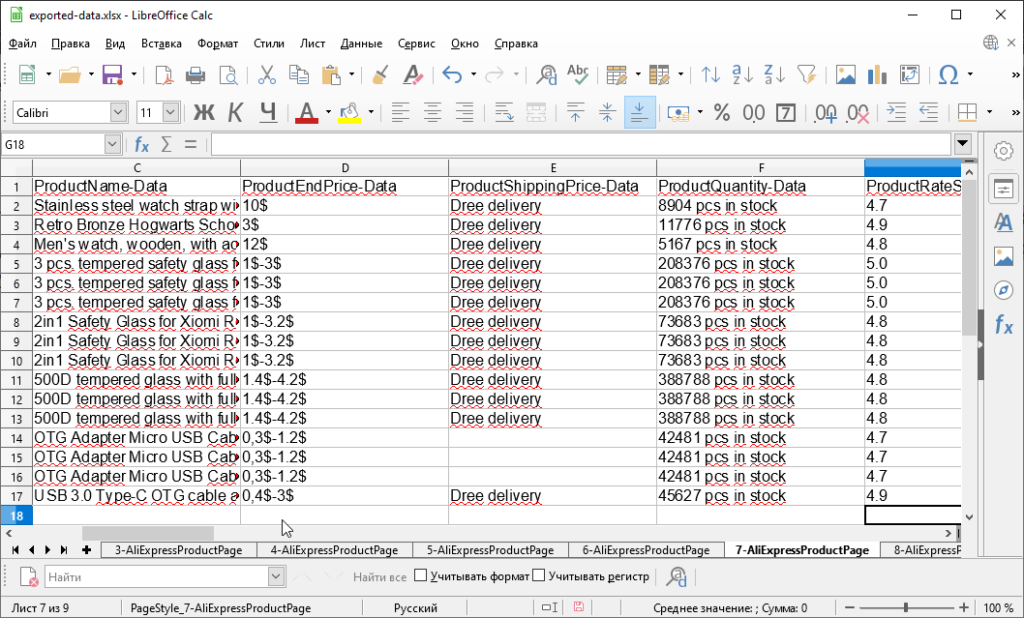
Actual project settings in DataExcavator application
As a matter of fact, all our settings for the project are separated in a separate configuration file. You can download this file and import it into DataExcavator. Do not forget to define the links that you want to bypass. Aliexpress is a very large website, which can be indexed for years. You need to highlight a segment of the products you want, and use only this segment to bypass.
Link to settings file: https://data-excavator.com/de-configlib/aliexpress/productpage-settings-08may2020.json
Quick instructions
So, you and I took a closer look at how our Aliexpress data scraper works. Now you can download our program and a ready-made script for scraping. This will allow you to extract the information you need. Thus, we suggest you follow the following path:
- Download our scraping server by the following link.
- Install and run DataExcavator.exe
- Download ready-made AliExpress scraping script by next link.
- Import scraping script (Main menu -> Import)
- Add a couple of links for crawling
- Run project
- Wait for a while
- Profit!
Are there any more questions? Always happy to help. Our contacts and feedback form are here. Also, FAQ is available here.