
So, today we will look at data scraping from Amazon.com. It’s the largest online store in the world at the moment. Here you can find almost any goods – from clothing to sophisticated technical equipment. Amazon offers its suppliers direct delivery of goods to the customer. They also provide a continuous flow of customers to their suppliers. Constant technological development and unrivaled service make Amazon a monopolist in many goods categories. And if you haven’t already bought goods from Amazon or worked with them as a supplier, it’s time to give it a try!
Working in the e-commerce segment, you will sooner or later face the challenge of data scraping from Amazon.com. This may be due to the need to compare prices with competitors or to increase your own website quality. What can we say? Sometimes it is easier to download your supplier’s products from a website than to spend a month writing to him and asking him for a price list with the prices and pictures.
Disclaimer
After reading this article, you will be able to extract data from Amazon automatically using our application.
Please note that this article has a significant technical gradient. If you just need to make a data scraper for Amazon website without unnecessary reading, you can go to the quick instructions at the end of this article or just contact our support.
Want to extract data from websites? You will need basic technical knowledge about .CSS selectors. You can find general information here (third-party site). In general, an understanding of .CSS selectors will help you to solve any task on information scraping.
Attention! This article is relevant for May 2020. All sites sometimes change their layout and the way they present information. If you now find that the method proposed here does not work, please let us know and we will quickly make changes. This is our job, and we try to keep the configuration repository up to date. Thank you!
What’s so special about our scraper?
We’ve looked at some competitors that offer Amazon scraping services. We think we can do it better and cheaper than many. We’ve looked into all the details of the scraping of this site, and we’ll tell you about them right now. What’s more, if you really need to scrape the information from Amazon – when you buy a key for a year as a bonus we’ll make you the settings of the scraper absolutely free!
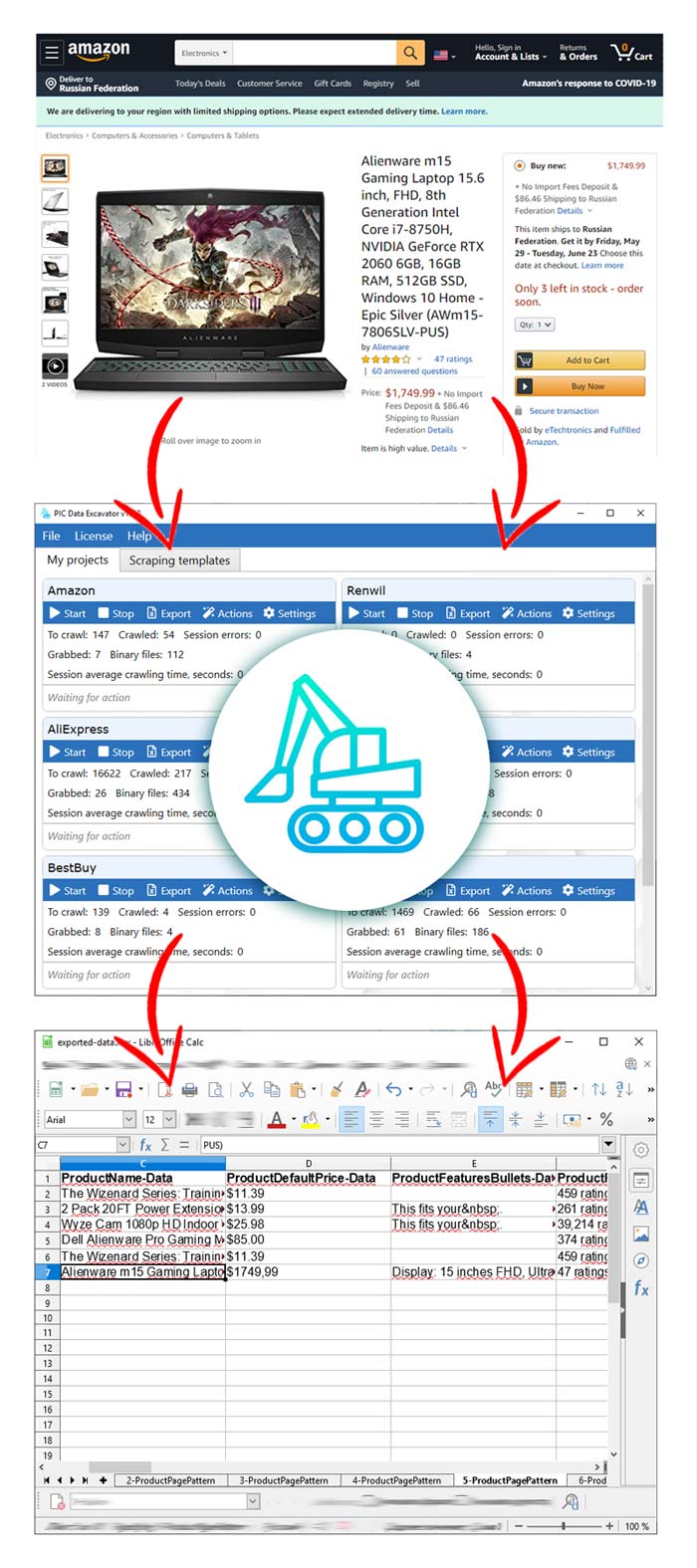
Our program scrapes data from Amazon.com in multiple windows (parallel threads). We have no limits on the number of pages processed. This means you can extract as much goods from the Amazon website as you want. At the same time, we support proxy servers, and you will not be able to be blocked. Our Amazon scraper is fast and easy to use for most existing website categories.
Want to know how it works? Keep flipping!
Scraping features of Amazon.com
So, let’s look at the issue in more detail. In terms of data scraping, Amazon is quite complex (but not for us!). First, depending on the product category, the page layout changes significantly. For example, pages from the category “music” have a fundamentally different look than, say, with pages from the category “clothes”. This is not surprising – each product has its own unique properties. For clothes, the most important properties will be color, size and style. For music, these properties do not exist at all. Music albums have other properties – there is a description, the author of the album and the year of release.
In terms of any scraping, this is the main difficulty in extracting data. For any software scraper, the differences in page layout are an essential detail. The point is that a scraper must clearly understand what data he should extract from certain parts of the page.
Amazon scraper – page structure
When we set up our Amazon scraper to extract data, we create a special configuration file. In this file, we determine from which elements on the page and in what order the data we need will be extracted. And for different goods categories on the Amazon website, the settings will be slightly different.
In addition, we should mention the behavior of the page itself. The product page is divided into several interactive blocks, which are independent of each other. When we scroll page downwards, various elements are loaded on it – description blocks, customer testimonials, additional features. These points should also be considered when extracting data from the website. If you simply upload a page and try to extract information from it, the result will be incorrect.
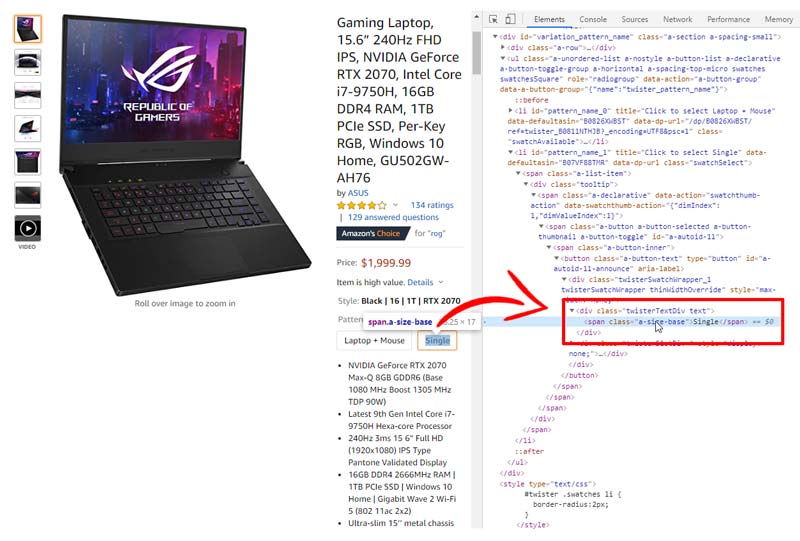
Our basic principle of data extraction is based on the use of .CSS selectors. In the settings, we tell the server from which nodes the data should be extracted. In the results, we get the data set as “Node name”: “Data in the node”.
The third difficulty is working with images. As we wrote above, sometimes we meet pages with several commodity options. In this case, each of the options often has its own set of images. Just go to the page and try to get the data from there – you will get a set of images only for the first option, chosen by default. We should also take note of that.
All goods are different
Have you ever bought a commodity without parameters? It’s becoming a rarity nowadays. Almost every manufacturer offers a wide range of parameters within a single product. We can choose exactly the thing we need from many parameters – colours, sizes, formats of suitable cables and anything else. Not only does Amazon support multiple commodities options by default, but its functionality is constantly being improved.
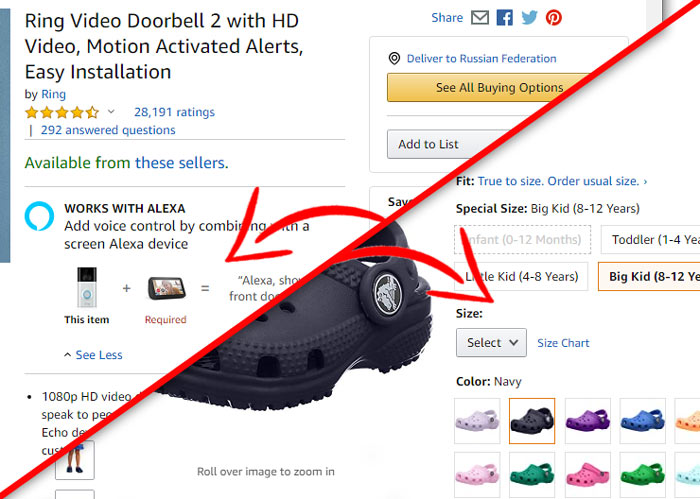
Each item category always has its own unique set of features. For some goods, color and size are important, while for others, electric power and CPU frequency are important. Amazon takes care of its customers by following the characteristics of each product category. Depending on the category to which the product belongs, the appearance of the page changes. By the way, that’s why Amazon has such a strong position on such a wide market. Every buyer sees exactly the parameters that are important in the category they are buying.
Twister – product feature selection unit
In terms of functionality, selecting a purchase on Amazon is a set of special buttons. The conditional name for these buttons is “Twister”. It is responsible for presenting all the options for the product it sells. If a product has several colors to choose from, each of them will be presented inside the Twister. If it has several sizes, they will also be available inside the Twister as a drop-down list. As a result, when you go to the page to buy a new shirt, you will be able to click on the button with your favorite shirt color and choose from the drop-down list the size that suits you.
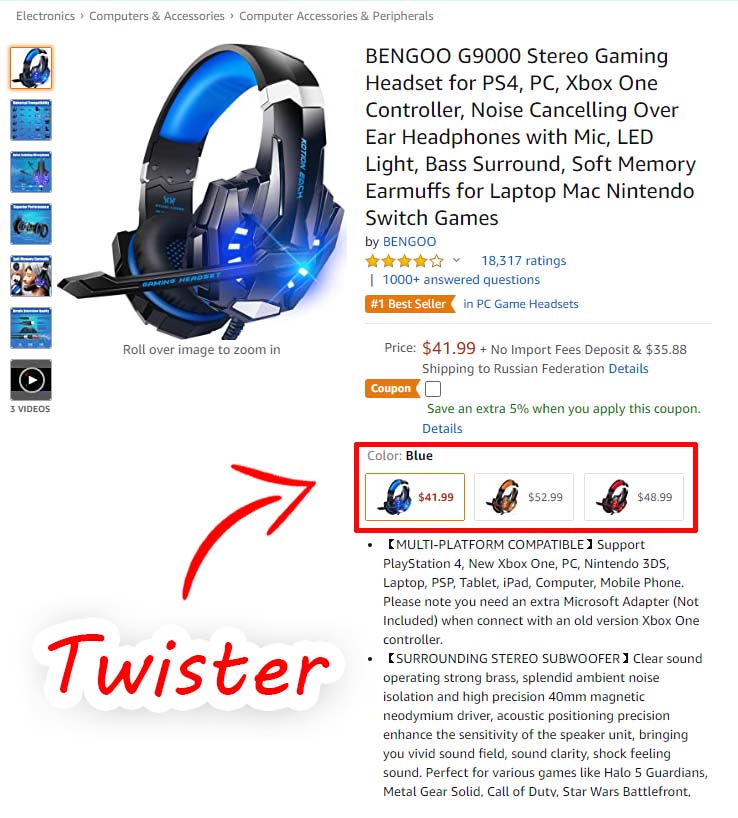
Sometimes, in the selection boxes, the price of the item is immediately displayed. This is particularly the case for computers, electronics, and some technical things in general. On the other hand – almost never the price is displayed in the color or style blocks.
Those pages that contain Twister, assume its mandatory use before buying the goods. In fact, you will not be able to add it to your shopping cart without selecting the product parameters.
Twister in terms of code is quite complicated and we do not fully understand it. We suppose, it is contained on most pages in one form or another. It is very likely that its structure and HTML markup are often changed by the company’s programmers. In any case, if you want to extract data from Amazon for practical use, whatever scraper you use, you’ll have to deal with Twister features.
Product pictures and videos
We divide the goods on Amazon into two large categories. The first category is the pages that do not have the Twister interactive block, and the pages that have it. If a page does not contain a Twister, it is usually a simple commodity without features. Otherwise, if the page contains Twister – it is a more complex product with a choice of some configuration.
If the page contains Twister – it means that the product is presented in several variants – it has several colors, sizes or other parameters. In almost all cases, each of the product options has its own set of pictures and videos. At a choice of a variant of the goods, also the set of pictures for this goods in a block of a preview changes.
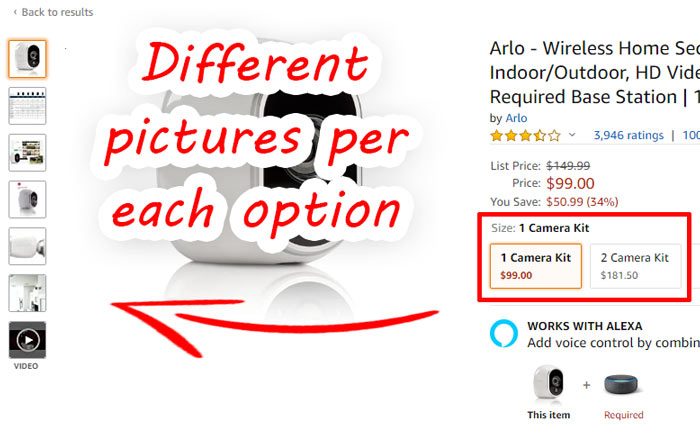
Let’s take, for example, this product with several options. Although at first glance each of the options should look the same, in fact it is not. When selecting specific properties, the product images are changed.
We believe that quality scraping of a product with Amazon should take this feature into account. Specifically, we have found a way to extract information from all product images, according to all its options. We will talk about this below.
Our approach to Amazon scraping
We extract almost all data from the product page on Amazon. Part of the information we get with the help of .css-selectors processing, and part – with the help of special script execution on JS. .CSS-selectors allow us to extract standard elements with good HTML structure, which you can use in the future without much difficulty. JS-script performs the role of HTML nodes preprocessing and extracts that part of the information, which can not be taken from the page directly, or that requires processing.
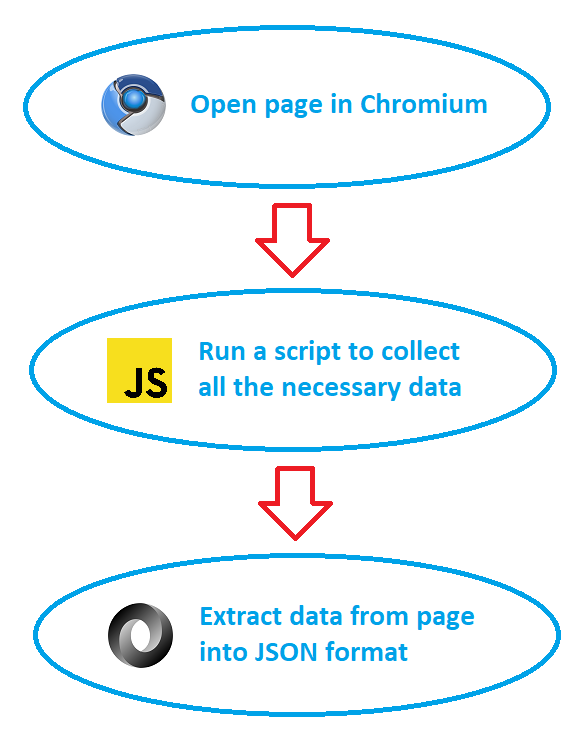
Our Amazon scraping algorithm starts 1-2 seconds after page loading is complete. First, we run our special JS script on the page. This script scrolls the page down and then starts preparing to extract information from the page. We do scrolling because it’s only with scrolling that Amazon displays some elements. Other JS scripts change the displayed content of the page so that you can get the desired data in a convenient way.
After performing scrolling downwards, we click on the “show feedback” button and repeat this action several times. Next, we extract the contents of the reviews. At the same time, we extract all the parameters and features of the products from several tables and blocks with parameters. Such blocks can include both the product description from the manufacturer and the table with product characteristics.
Going deeper – twister analysis
Further, we go through all the elements of twister, and extract all the options of the goods. It can be colors, characteristics, sizes, or anything else. For each of the options, we look for the corresponding set of pictures and make a comparison with the option. This allows us to make a table of the “Commodity option – Picture Set” view.
As a result, on the page at the bottom of it, our Amazon scraper adds a few additional HTML blocks with text, which was prepared by our JS-script. These blocks contain information about all product parameters in a convenient structured form. Also, the blocks contain information about all images of the product and other compressed information. The next step is our Amazon scraper to save this data to your hard drive.
We sure, all this can be done in a much simpler way. You can avoid scrolling through options, searching for pictures, preprocessing nodes on JS, and other complex issues. It all depends on what level of results quality you need. If your task is surface data, you can simplify all this and extract only a set of images for the first product option. And vice versa – if you need literally all the data in the form suitable for the quality of further use – you will have to work hard. Fortunately, in this case our Amazon scraper can make this task much easier.
Picture extraction – ImageBlockBTF, ImageBlockATF.
A little bit above we wrote that our Amazon scraper collects all images, comparing them with product options. We would like to share with you our approach to solving this task.
In order to collect all images of the product, you will have to refer to the source code of the page. We need to find a special markup, which initializes all images of the product. In the source code of Amazon.com source pages you can find these places by the ImageBlockBTF and ImageBlockATF substrings. Judging by our analysis, these code blocks are responsible for storing media data on product pages. And while ImageBlockATF usually represents products with minimal or no properties, ImageBlockBTF is intended for storing images for complex products with a wide range of parameters.
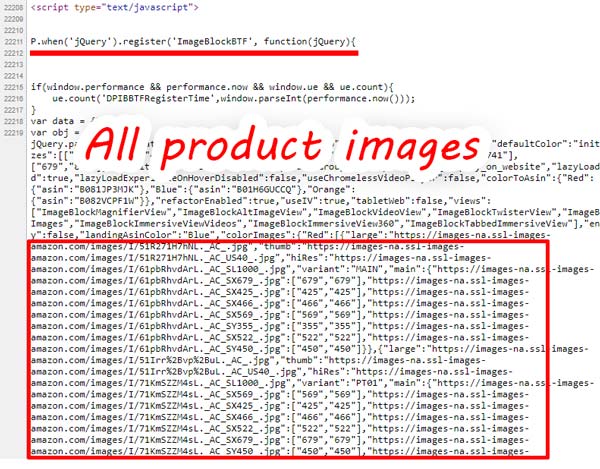
After loading the page we turn to ATF and BTF blocks, and with the help of substrings we extract the internal part of the program initialization of these data. After that, we use the eval function to reinitialize this data, making it available from external code. Once we have access to this information, we line it up and place it in a regular HTML block.
Results – export the collected data
After completion of the basic algorithm, our application provides an opportunity to export results in a convenient format. It can be Excel, JSON, CSV or MySQL. In case of Amazon scraping, we usually use the .xlsx or JSON export format. With this option, we get about the following.
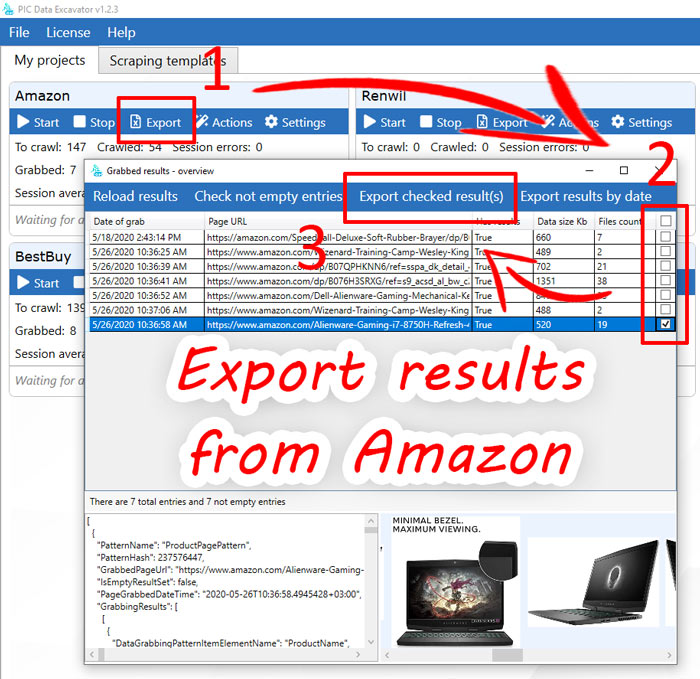
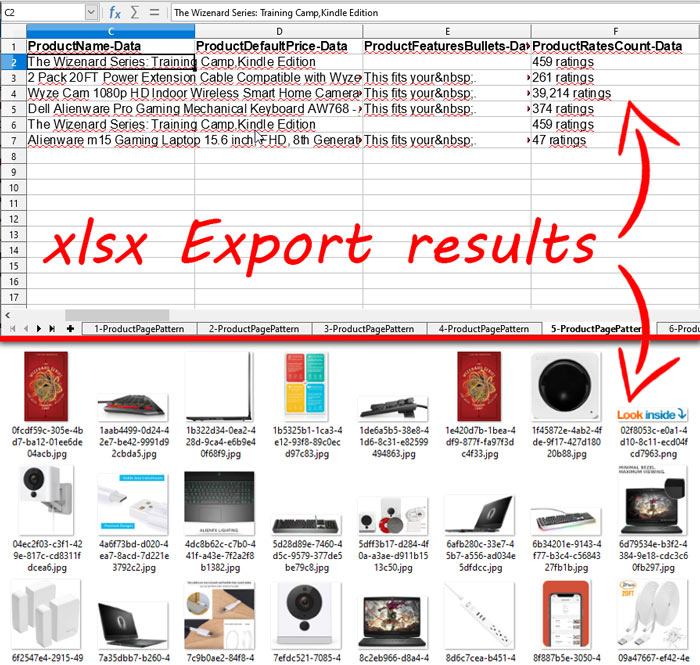
In the results folder we see the exported.xlsx file and the pictures folder. Inside the xlsx file there is a special column, which contains comma names of picture files.
Note that in many cases it is more convenient to export results to JSON-format. Given the complexity of the structure of amazon pages, the file contains a large number of columns. In JSON-view it is more convenient to work with this data. If you decide to export results to xlsx or csv, keep in mind – if you have several results on some element of the site, in the exported data such results will be separated by a comma.
How do I use your Amazon scraper?
We have prepared a ready-made configuration file for you to scrape the Amazon.com website. All you need to do is download our application, install it, and import the settings. After that – enter the links to the pages you want to get the data from. The server will download these pages, extract the data from them and you can export the results as you want.
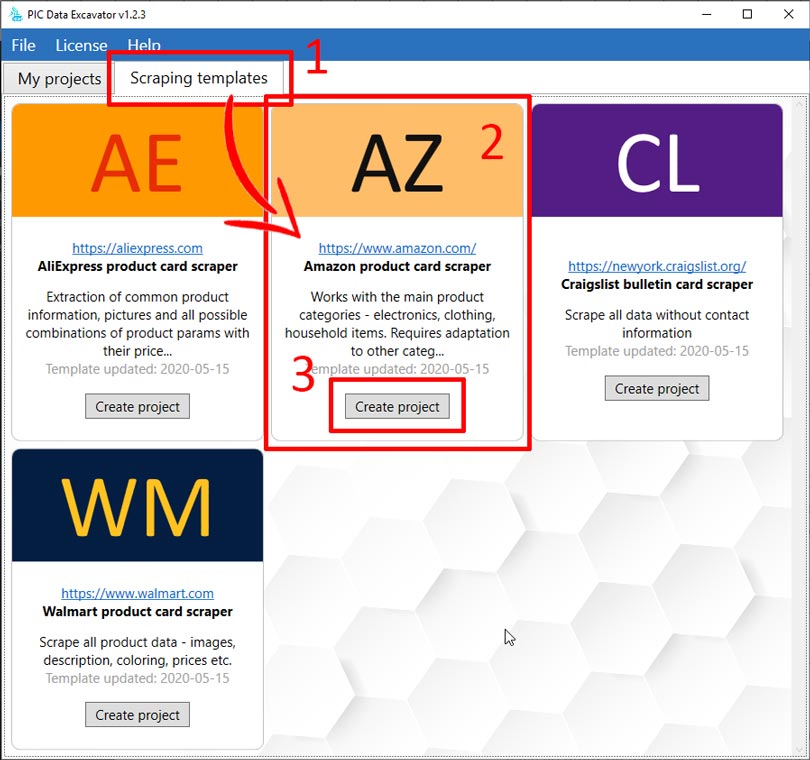
In recent versions of our application we have added a library of ready-made templates. In this library, you can also find a ready-made project for scraping the Amazon. By clicking on the “create project” button inside the template card, you will get a ready-made project with settings that remains to be run.
Please note that we are talking about a very large website. Before you start extracting the data with our Amazon scraper, you will need to define the categories of products that will bypass the server. The server will only retrieve information from products that are in the specified categories. Alternatively, you can manually enter links to the pages you need. Otherwise (if you allow the application to analyze the entire site), it will take a very, very long time to extract all data from the Amazon site. Given that a site consists of millions or even billions of pages, it may take you several years to fully bypass it.
Our demo key is enough for you to get acquainted with our application. We have no limits on the total number of pages downloaded or the download speed. We use a licensing model that is based on the number of simultaneously working threads (windows). The demo key allows two windows to work simultaneously. The validity period of this key is one month from the moment it is sent to your e-mail.