
Sometimes in life there are situations when you need to extract a lot of data from some website. It can be product cards, social networking messages, .pdf documents, videos, or anything else. You can of course do this manually, or hire programmers to automate such a task. But also, you can use our application and solve this task quickly, inexpensively and elegantly.
Our app is an installable data scraper that works from your computer. There are no cloud servers, strange tariffs or numerous instructions. There is a simple and straightforward solution, which works quite universally and quickly.
The basis of our project, formally speaking, was established in 2012. That’s when we first encountered data scraping. Since then, we’ve been working on many projects, and in 2019 we decided to completely rewrite the existing core for scraping and isolate it into a separate project. We have now completed the alpha testing phase and are in the late beta phase. The application is stable and we are actively collecting feedback and opinions on its further development.
What are our advantages?
Quality and performance. We think that our application should be simple and powerful enough to be a tool for scraping. We want to create a really convenient and fast tool that would allow us to extract large amounts of data without complicated technical settings. We do not want to complicate things that should not be complicated. We want to help people extract data, not make them sit on forums for hours or wait for the scraping limit in their cloud service to expire.
Inexpensive. Our product has the lowest subscription price in the marketplace. On average, the price of scrapers on the market is $50-$150 per month. Our current price is $150-$150 a year. At the moment we have a small team, and in general, our audience is increasing without advertising. This allows us to offer exactly these prices.
Awesome support. Scraping is often a headache for customers. Fortunately for us and unfortunately for our clients, many companies in this market work on the principle of “buy an application and go read instructions”. Well, we think a little differently. To start with – buying a license key, you can count on one free package of settings for the site from which you need the data. We will make these settings and send them to you for import into our application. Secondly, we place great emphasis on good technical support. We advise by e-mail, whatsapp, skype. If necessary, our specialists are ready to connect to your computer via RDP / TeamViewer and help you with our application.
What else?
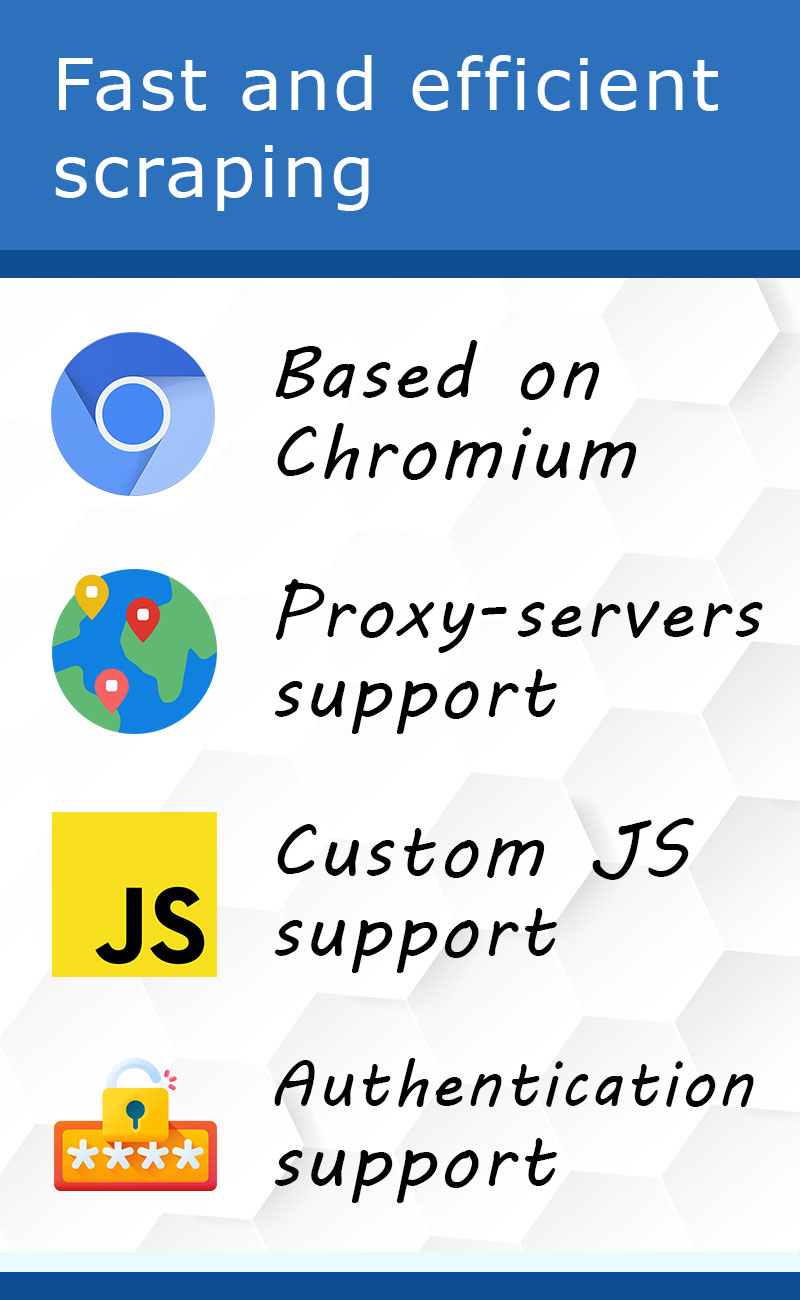
From a technical point of view, our application allows you to extract data from several sites simultaneously. This is parallel scraping. The extraction process itself is based on .CSS selectors and XPath expressions. The program works well not only with HTML code, but also with files. We are able to download images, .pdf files, documents and any other binary data. The program also includes many useful and convenient options – JS-interaction with the site, authentication mechanisms by login and password, support for proxy servers and much more. All this allows us to solve the most complex tasks quickly and efficiently.
You can download the app at this link. Note that the application runs only in Windows environment.
A fully-functioning demo of the application isavailable for a 30-day evaluation. You can find it here: https://data-excavator.com/get-demo/
We will be glad to see you among our clients!
 |  |
|  |