
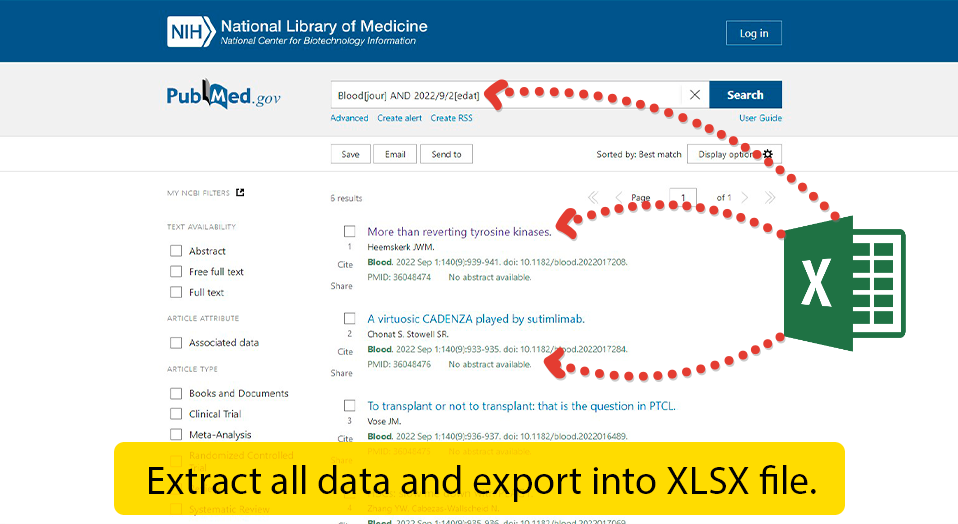
Pubmed data scraper is an application for automatic data extraction from Pubmed. You can use it to scrape almost any data from Pubmed, and save it to an XLSX file. Shortly – It’s the same as if you copied the information with mouse, only automatically.
Pubmed is a site created by the National Center for Biotechnology Information (NCBI) and is an electronic search engine with free access to 30 million publications from 4,800 indexed medical journals. The database contains articles published from 1960 to the present day. More than 500,000 new papers are added to the portal each year.
Why scrape data from Pubmed?
Pubmed what is the reason for scraping it ? More often than not, we have several options for it. The first is to fill our own site with articles on the topics we need. You can fill your thematic group with new material. Secondly, it is a research work related to the collection of statistical information. We also use scraping for personal purposes.
So, at the bottom line. The main goal of Pubmed data scraping is to attract an audience to your project. Secondly, to gather a database for active sales, or to analyze the data for some scientific purpose. In any case, data scraping helps you make good money in a short period of time.
Is scraping Pubmed legal?
It is absolutely legal to scrape publicly available data such as product descriptions, prices, ratings, or reviews. So yes, scraping any publicly available data from Pubmed is legal. But wait, it’s not that simple.
In fact – from a legal standpoint, scraping restrictions may arise in the extraction of personal data. Be careful when extracting information such as username, phone number, address, e-mail, and the like.
Pubmed data scraper is an automatic program that emulates user behavior. in summary, It is just as legitimate as if you were manually copying information line by line.
What data can I pull from the Pubmed pages?
Obviously, we have a simple answer. You can scrape almost any kind of data from Pubmed. Literally, anything you want. Just click on the items on the page, and start the scraper. As an example, here’s a list of fields we extract from Pubmed:
- Article
- Title
- Description
- Date of writing
- PMID
- DOI
Also, please note. This is only a sample list of fields. You can add or remove any fields for scraping. And yes, it’s very easy to do. All you have to do – is click on items on the page.
How do I start with Data Excavator?
Basically, to use Pubmed scraper you need to download our main application – Data Excavator. This can be done in the download section (clickable).
Firstly, install the Data Excavator app. Note that the application runs in a Windows environment. You need the .NET Framework 4.7.2 (Can be downloaded here) and VC++ Redistributable 2019 (Can be downloaded here) packages installed for scraper to work correctly.
So, you have downloaded and installed the application. Now you need a demo key for a month of free work. You can get it inside the app, or go to the section to get the demo key (clickable). Fill in the Email field and your name. Then, we will send you the key to your email.
Finally, launch the application. Click the “New Project” in the main menu. Enter the link to any Pubmed page. Then, select the items you want to extract. Just move the mouse over the page and click on the items. Sounds easy, doesn’t it?
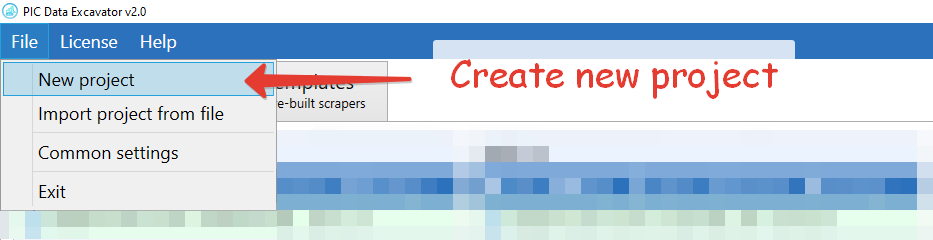
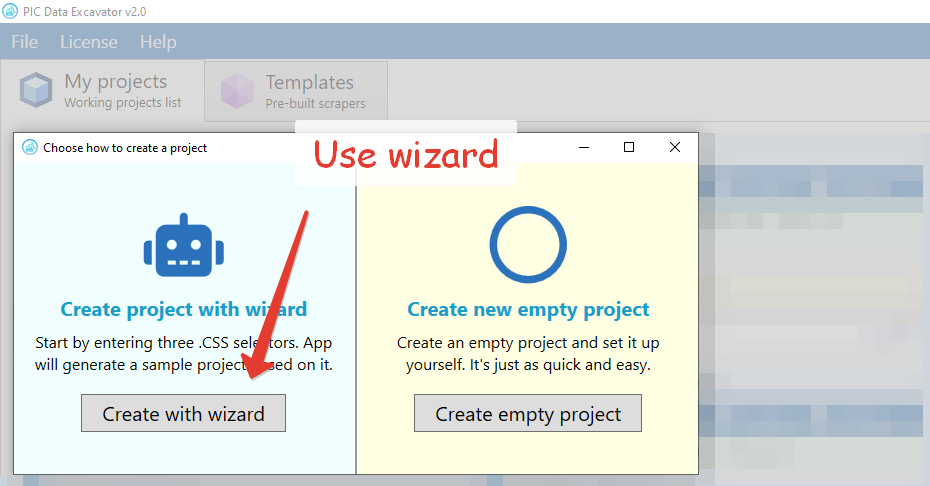
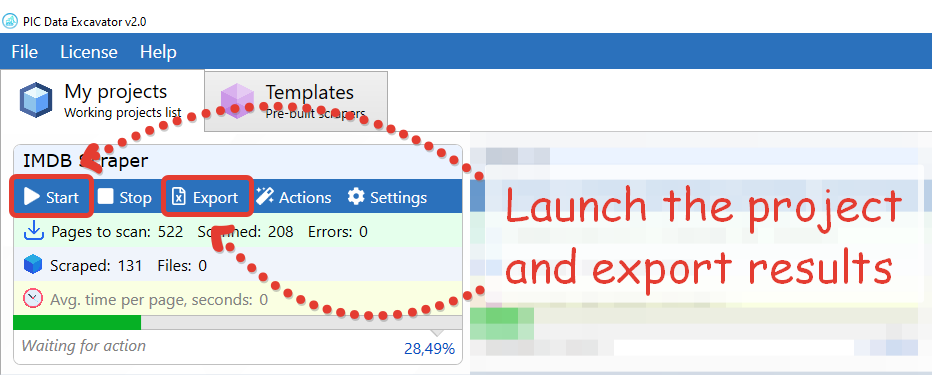
So now you have an idea of how to use the Pubmed data scraper. As you can see, it is not very hard. Despite the fact that scraping seems complicated – it is not always so. And our application demonstrates it perfectly. It’s as easy as clicking on a page and pressing a few buttons. We hope you enjoy the experience.
What else?
In fact, you can scrape any amount of data from the Pubmed website. It will be fast, inexpensive, and most importantly, legal. Just use our app, and follow the instructions.
In case you have any difficulties. Just contact us! At the very least, we’ll have a great conversation. At the most, we will solve your problems. Moreover, we can get great emotions from working together! So, you can contact our support team through feedback (clickable).
And finally, a selection of quick links. Have fun scraping!