
C# web scraping library
ExcavatorSharp - powerful scraping server
Our library is a complete solution for C# web data scraping. So, under the hood you will find crawling server & parsing server, css-selectors and x-path support, js support and much more. All code is written in strict multithreaded style. Yes, and the most delicious – our .NET library is based on Chromium.
public class ESHelloWorld { public void ParseWalmartAnyPage() { //1. Initialize tasks storage CEFSharpFactory.InitializeCEFBrowser(); DataExcavatorTasksFactory TasksFactory = new DataExcavatorTasksFactory(); TasksFactory.InitializeExcavator("Vbk4eQWp8kdmqnl2QlzWkBWIQzu++xD6yEwYB68SiEFVSOyRL0fEB0T7XlheB93/rRWdFtsnoHeiUu0WcVYHqqCZzPq0s0APf6KkND8B3N6ZL0yZ+vQsvvTCFf+SYADDMcW1RQLKHh+r03w+BOulu6nCM0sSHGDtqSiUGpjSa1RA4DLdSnGW7pTbXuqI2CGs"); //2. Create your first task DataExcavatorTask NewTask = new DataExcavatorTask( "My first scraping task", "https://www.walmart.com/", "Scrape some data from walmart", new List<DataGrabbingPattern>() { new DataGrabbingPattern() { PatternName = "Apple ipads pattern", AllowedPageUrlsSubstrings = new string[] { "ip/" }, GrabbingItemsPatterns= new List<DataGrabbingPatternItem>() { new DataGrabbingPatternItem("Item name", new GrabberSelector("h1.prod-ProductTitle", DataGrabbingSelectorType.CSS_Selector)), new DataGrabbingPatternItem("Item price", new GrabberSelector(".prod-PriceSection .display-inline-block-m .price-characteristic", DataGrabbingSelectorType.CSS_Selector)) } } }, new CrawlingServerProperties() { RespectRobotsTxtFile = false, RespectOnlySpecifiedUrls = new string[] { "ip/" }, PrimaryDataCrawlingWay = DataCrawlingType.NativeCrawling }, new GrabbingServerProperties(), "C:/ExcavatorSharp/FirstProject" ); //3. Subscribe events NewTask.PageCrawled += NewTask_PageCrawled; NewTask.PageGrabbed += NewTask_PageGrabbed; //4. Add links to crawling and start task TasksFactory.AddTask(NewTask); NewTask.AddLinksToCrawling(new List<string>() { "https://www.walmart.com/ip/Apple-10-2-inch-iPad-7th-Gen-Wi-Fi-32GB/216119597" }); NewTask.StartTask(); } /// <summary>Fires when some data from website been extracted</summary> private void NewTask_PageGrabbed(PageGrabbedCallback GrabbedPageData) { Dictionary<DataGrabbingPattern, DataGrabbingResult> GrabbedResults = GrabbedPageData.GrabbingResults; //Do what you want with grabbed data } /// <summary>Fires when some page from website been downloaded and parsed to structured HTML</summary> private void NewTask_PageCrawled(PageCrawledCallback CrawledPageData) { //... just take crawled data or skip this event. Additionaly, you can prevent page grabbing if you want (CrawledPageData.PreventPageGrabbing = true;) } }
Library features
ExcavatorSharp implements the full cycle of data scraping. Our C# web scraping library is organized as a data processing server. First of all, we work with the web crawling server, move to the parsing server, and finish with the export module. Look at what this library can do:
Multi-threaded
The library is written in a strict multithreaded style. Each module has isolation and its own thread pool. Modules interact through buffers.
Javascript ready
We use browser engine. You get an opportunity to scan websites displaying dynamic content through JavaScript or other ActiveX.
Data Export
You can export the results in the formats you prefer - .csv, .xls, .xlsx, .sql, .json. Extra bonus - exporting "On the fly" via http(s) link.
Proxy support
ExcavatorSharp supports proxying. At your service is an algorithm for dynamic rotation of a set of proxy servers. Emulate smart proxies.
C# events model
Two basic system events - "page scanned" and "page scraped". Subscribe to the events and get ready-made data sets online.
Chromium based
Solution is based on native C# scanning and Chromium Embedded Framework. This allows you to interact flexibly with the pages of your sites.
Robots.txt support
Full support for robots.txt, including correct handling of "Clean-param" and "Crawl-delay" directives. Automatic file reanalysis.
Sitemaps support
Full support for the sitemap files. Work with index files, support for archive files. Ability to manually linking to sitemap.
Compression support
Support for gzip and deflate content compression. Focus on the results of the scraping - our solution will solve all other problems.
Images scraping
The library supports downloading of any binary files, including images. Works correctly even if the data is specified into an attribute.
Interact with JS
Interact with the target website via JavaScript - do scrolling, clicking, posting forms, anything! The library gives full access via JS.
References management
The solution supports functions of intellectual references management. Add reference sets, send sets to re-indexing, force re-indexing.
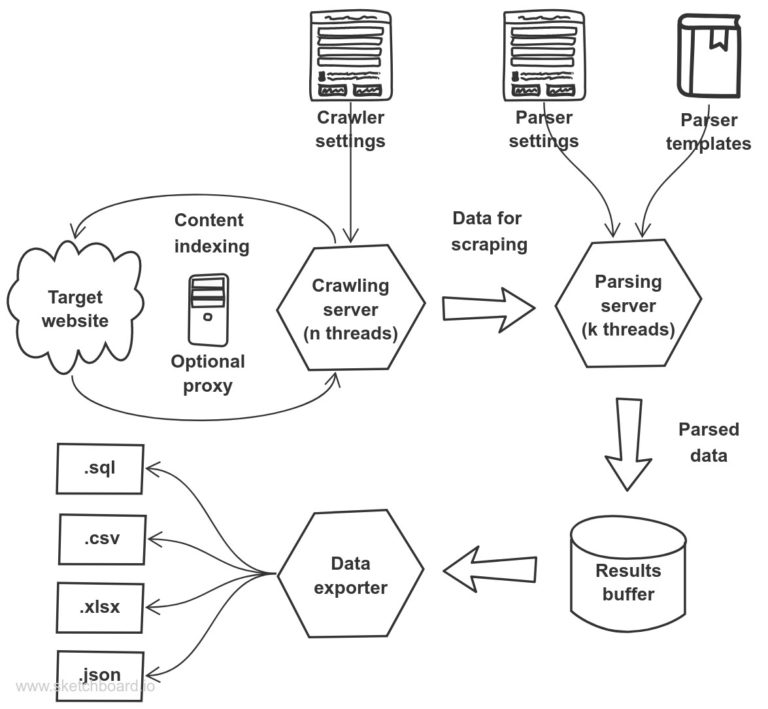
How it works
It should be noted that our C# web scraping library is divided into three large modules. The first module is a data crawling server. It is responsible for downloading pages and interacting with websites. The second module is a parsing server, which extracts data on a set of templates and patterns. Finally, the third module – data exporter. It converts multidimensional arrays of information into structured files or exports them online. For example, we fully support .json/.csv/.sql/.xlsx formats.
Each module has strict isolation and is made in multithreading style. Multithreading corresponds to good architectural practices of C# language. All modules interact through data buffers. As a result, the system has a stable and independent architecture. Each module performs strictly defined tasks.
Why ExcavatorSharp, not other libraries?
This C# library was conceived as part of a real large search engine. Well, although we didn’t have a commercial search engine, we are happy to suggest you use it for data scraping.


(… If you don’t get the humor, ExcavatorSharp library is an excavator on the left)
| ExcavatorSharp | Other libraries | |
|---|---|---|
|
Mission |
A complete scraping server |
A partial solution |
|
Library core |
Isolated CEF and .NET sockets |
Chrome connector or sockets only |
|
Architecture |
Pure multithreading |
Only one thread |
|
Scraping morel |
Events-based (parallel in and out) |
Linear (invoke and wait) |
|
Perfomance |
Unlimited parallel threads |
Limited by one thread |
|
Proxies support |
Yes - smart proxying & proxy pool |
No, one proxy or partly support |
|
Scraping dynamic content |
Yes |
Partly |
|
Interact with websites |
JS interaction level |
No, or browser interaction level |
|
Difficulty |
Middle -> High |
Low |
|
Scraping technique |
.CSS-selectors and XPath |
Mostly, only XPath or only CSS |
|
Crawling technique |
Complete crawling server |
Linear (send link and wait) |
What about pricing?
We hope you’re ready and focused. As a basic plan we offer a completely free demo plan for 5 projects and 2 threads. The demo plan is not limited in time and number of scraped pages. It has no limits at all! Start working with the web scraping library right now! If you want a little more professional work, really powerful multi-threading and support – then the basic plan will suit you for 125$. Usually, you should start with a free library for a brief introduction. Then, decide on the applicability of our library to your web scraping task.
StartUp
- Upto 10 projects into app
- Upto 4 threads per peroject
- No crawling speed limits
- No crawled data limits
- Without support
Standard plan
- Upto 50 projects into app
- Upto 15 threads per peroject
- No crawling speed limits
- No crawled data limits
- Email support
Enterprice plan
- Unlimited projects into app
- Unlimited threads
- No crawling speed limits
- No crawled data limits
- Email + extended support
Technical documentation
We’re just launching our C# / .NET scraping library into commercial access. We want to understand how much people will need it. That’s why we don’t have a lot of technical documentation. Just a few basic examples. Perhaps, some simple code samples are better than a lot of scientific text. The documentation is available by this reference. However, the software code inside the library is well documented.
Download
Warning! The x64 assembly can be correctly installed and launched only if the platform is configured correctly. The assembly will NOT work when AnyCPU is set! Only x64! Be attentive!
C# web scraping library applicability
ExcavatorSharp web scraping library is pretty simple. It perfectly applicable as a basic infrastructure for any C# or .NET project. For those projects that needs to extract web data. We use the “Event” model, coupled with pure multi-threading and logical block isolation. Thats why it allows us to process really large amounts of data very quickly.
You can use our C# web scraping library for extracting information from most sites. For example, you can scrape data from e-commerce sites, message boards, chat rooms, social networks, stock exchanges, cryptocurrencies sites and so on. You can scrape whatsoever both online and in the background, and then export it. It does not matter how the website is organized – lists, cards, “tiles”, dynamic content or anything else. Scraper can do any task perfectly.
The crawling server is your own factory for page bypassing and link analysing. Parsing server is a complete module for fast data parsing using .CSS or XPath. Proxy server pool support – great solution for industrial crawling. Interaction with sites via JavaScript and scanning of dynamic content is an integral part of modern scraper. And let those who talk about C# imperfection be amazed by the performance and flexibility of solutions written in a pure and inspirational way.
Contacts
Want to discuss something or buy a commercial license? Please email info@mail.data-excavator.com or dataexcavator@yandex.ru. If you want to talk in your voice, please also write. We can agree on the time and method of communication.
What else?
ExcavatorSharp UI
Need a full interface to work with the library? Do you regularly scrape a lot of web data? Take advantage of our product - DataExcavator - a ready-made application for data scraping.
DataExcavator.ONLINE
One of our activities is the Data as a Service (DaaS). If you need data, but do not want to do programming, we will be glad to help you! Scrape any data online and got it into your infrastructure.
Educate scraping
From time to time we provide training in professional web data scraping. If you want to learn it, please contact us and we will agree on a training opportunity. Data hunting is open!
Powered by DataExcavator https://data-excavator.com
The information on the website is not a public offer
Direct e-mail contact: info@mail.data-excavator.com